Scrapingbee

Content
Frequently Asked Questions About Web Scraping
We are using BeautifulSoup for web scraping and of course unittest for testing. This chapter explains tips on how to carry out testing utilizing web scrapers in Python.
How Is Web Scraping Used In Business?
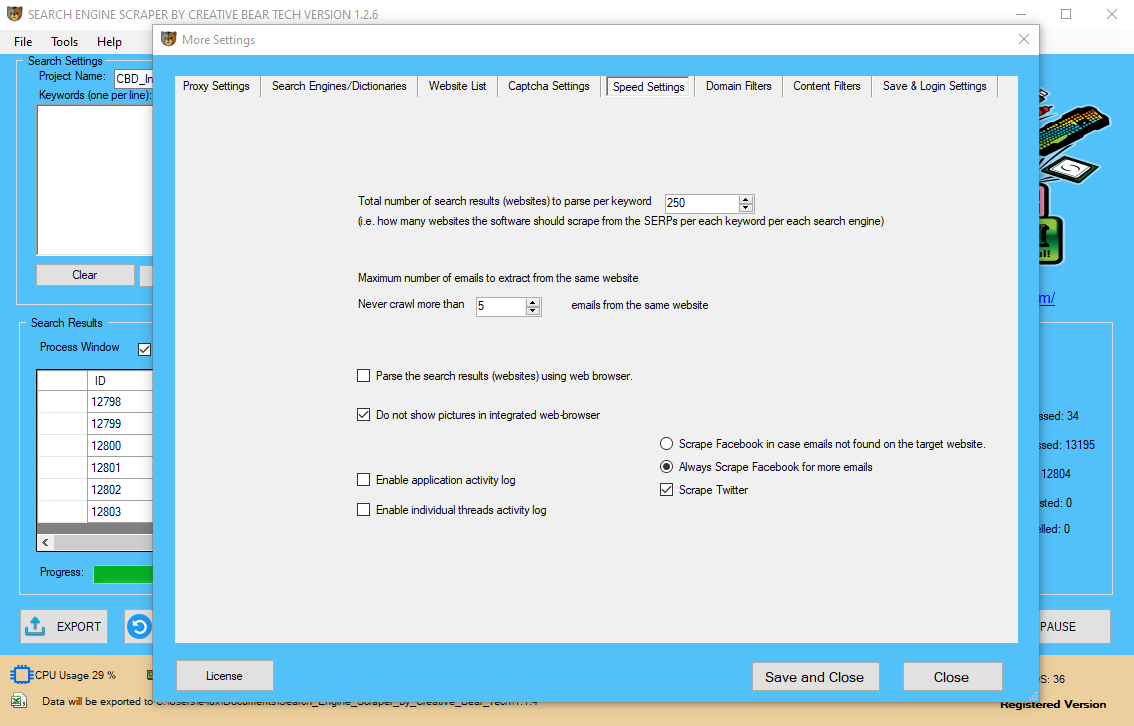 Our services make requests utilizing 1000's of residential and non-residential rotating proxies across the World to provide the best scraping expertise and fit all of the enterprise wants. There are a couple of essential elements of web scraping that usually get missed. A fixed provide of IP addresses that belong to actual units is the golden key that can make your project successful. Contrary to frequent belief, scraping public and factual data is authorized.
Our services make requests utilizing 1000's of residential and non-residential rotating proxies across the World to provide the best scraping expertise and fit all of the enterprise wants. There are a couple of essential elements of web scraping that usually get missed. A fixed provide of IP addresses that belong to actual units is the golden key that can make your project successful. Contrary to frequent belief, scraping public and factual data is authorized.
Is Web Scraping Legal?
All we'd like is an outline of your information scraping project, together with the output frequency - should you'll want the info to be scraped monthly, weekly, day by day or simply once. If you need to log in to have access to this knowledge, knowledge scraping is illegal. Also, how you're technically scraping the website matters a lot. Our headless Chrome browser settings and proxies high quality enable us to make site scraping requests with low chance of Captcha verify triggering.
What Are The Best Tools For Web Scraping?
A language includes lots of variations as a result of grammatical reasons. For instance, think about the phrases democracy, democratic, and democratization. For machine learning as well as for net scraping initiatives, it is important for machines to understand that these totally different phrases have the same base kind. Meaning that the JS will behave nicely inside a scanning setting and badly inside real browsers. And this is why the team behind the Chrome headless mode are attempting to make it indistinguishable from an actual person's web browser to be able to stop malware from doing that. And that is why net scrapers, on this arms race can profit from this effort.
USA Marijuana Dispensaries B2B Business Data List with Cannabis Dispensary Emailshttps://t.co/YUC0BtTaPi pic.twitter.com/clG0BmdFzd
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Use Docker/Kubernetes and public cloud provider like AWS to simply scale your internet-scraping backend. You’ve seen tips on how to extract easy items from a web site utilizing Scrapy, however that is simply the floor. By incorporating web scraped product knowledge into on a regular basis enterprise, agents and brokerages can protect towards high-down on-line competition and make knowledgeable decisions inside the market. Market analysis is crucial – and should be driven by essentially the most accurate data out there. High high quality, high quantity, and extremely insightful, internet scraped data of each shape and measurement is fueling market evaluation and enterprise intelligence across the globe. A cookie, typically known as net cookie or internet cookie, is a small piece of knowledge sent from a web site and our laptop shops it in a file positioned inside our net browser. In this chapter, let us perceive scraping of websites that work on consumer based mostly inputs, that's type primarily based web sites. Web scraping is a posh task and the complexity multiplies if the web site is dynamic. According to United Nations Global Audit of Web Accessibility more than 70% of the web sites are dynamic in nature and so they depend on JavaScript for his or her functionalities. The minimal request delay time usually could be found within the robots.txt file of an internet site. Data mining is the method of discovering patterns in giant information units which is often accomplished by implementing a machine studying solution. Web scraping is singlehandedly one of many extra environment friendly methods of gathering giant data units, and after web scraping and knowledge wrangling you'll have an analysis-ready information-set. Skip to this part of the article if you’re just in search of some fast answers to the most typical questions about API scrapers. Our opponents usually restrict the number of requests you may make to their web scraping API. One of the most popular options, for example, solely allows ten requests in parallel. Here at Scraping Robot, our API has the identical performance with no such restrictions. In this part, we are going to discuss about useful Python libraries for net scraping. Another cause for using Python for net scraping is the inbuilt in addition to exterior useful libraries it possesses. We can perform many implementations associated to web scraping by using Python as the bottom for programming. Once you register, you'll have 6 months to finish the course. If you visit the course 6 months after your preliminary registration, you will want to enroll within the course again. We are teaching you how to do that utilizing Python in the course however be at liberty to use R if that’s your language of alternative. You can go through this tutorial that walks you thru the way to master net scraping utilizing an R package deal called rvest. From automated pricing solutions to worthwhile funding insights, this information moves mountains. Browse our use instances or take a look at our white papers for extra info into how this superb expertise is fueling tomorrow’s business options. We often replace the “Introduction to Web Scraping using Python” course and hence don't allow videos to be downloaded. You can full the “Introduction to Web Scraping using Python” course in a few hours. How lengthy would I actually have access to the “Introduction to Web Scraping using Python” course? The Dark and Deep Web Data Scraping incorporates these web sites that can not be listed by search engines like google or pages that can't be detected by internet crawlers. It comprises of data-pushed websites and any section of an internet site that's beyond a login web page. Most of the time, when a Javascript code tries to detect whether or not it is being run in headless mode is when it's a malware that is attempting to evade behavioral fingerprinting.
Are you looking for CBD capsules? We have a wide selection of cbd pills made from best USA hemp from discomfort formula, energy formula, multivitamin formula and nighttime formula. Shop Canabidol CBD Oral Capsules from JustCBD CBD Shop. https://t.co/BA4efXMjzU pic.twitter.com/2tVV8OzaO6
— Creative Bear Tech (@CreativeBearTec) May 14, 2020
Bag of Word (BoW), a useful model in natural language processing, is basically used to extract the features from textual content. After extracting the features from the textual content, it can be used in modeling in machine studying algorithms as a result of uncooked information can't be utilized in ML purposes. In the first chapter, we've learnt what internet scraping is all about. In this chapter, let us see the way to implement web scraping utilizing Python. After all these steps are successfully carried out, the net scraper will analyze the info thus obtained. In this step, a web scraper will download the requested contents from multiple net pages.
- So information mining with this web site scraping software has become a sensible selection for business.
- There are so many data scraping instruments can be found on the web to scrape websites knowledge.
- Anysite Website Extractor will allow you to to focus on your core enterprise operations and thus improve total productivity.
- This site scraper helps businesses to gather and manage their data successfully, which in flip permits them to attain higher profits.
That’s a key purpose why knowledge scientists are expected to be familiar with internet scraping. This course will cover all these aspects of internet scraping and showcase how to perform web scraping using BeautifulSoup and Scrapy. My final objective is to deliver a superb finish work that can add worth to your corporation and take it to larger heights. The most essential characteristic of a scraping script may be the flexibility to adapt and even stop scraping if required, a scraping software ought to never proceed after triggering detection mechanisms. To process the info that has been scraped, we should retailer the data on our local machine in a particular format like spreadsheet (CSV), JSON or typically in databases like MySQL. The owner of the website additionally issues because if the owner is thought for blocking the crawlers, then the crawlers have to be careful whereas scraping the info from web site. There is a protocol named Whois with the assistance of which we will discover out about the owner of the website. Of course, you should pay attention to the info you’re scraping and always check with the location’s robots.txt file, which tells search engine crawlers which pages or information the crawler can or can’t request from a web site. Scraping a website towards the directions in its robots.txt might be illegal in most nations. While you can use it for a enjoyable knowledge project, many companies depend on web scraping more than you’d think. Scrapy provides lots of powerful features for making scraping straightforward and efficient. Here is a tutorial for Scrapy and moreover Here is the documentation for LinkExtractor by which you'll be able to instruct Scrapy to extract links from a web page. Scrapy is an online crawling framework for builders to write down code to create spiders, which outline how a sure web site (or a group of websites) might be scrapped. Moreover, it's a framework to put in writing scrapers as opposed BeautifulSoup which is only a library to parse HTML pages. By making use of the information abstraction course of, you can simply extract and filter the required data from the information. Newer forms of net scraping involve listening to knowledge feeds from internet servers. For example, JSON is usually Facebook Email Scraper used as a transport storage mechanism between the consumer and the web server. Crawls arbitrary web sites and listing utilizing the Chrome browser and extracts structured data from web pages. The most basic way of not getting blocked when scraping a web site is by spacing out your requests so that the web site would not get overloaded. If you have a basic idea of what knowledge you need, we might help you pinpoint essentially the most related web sites which might be value scraping, be it review platforms, social media or e-commerce platforms. If you know what kind of knowledge you want, e.g. all automobile crashes in New Zealand, we may help you get it. 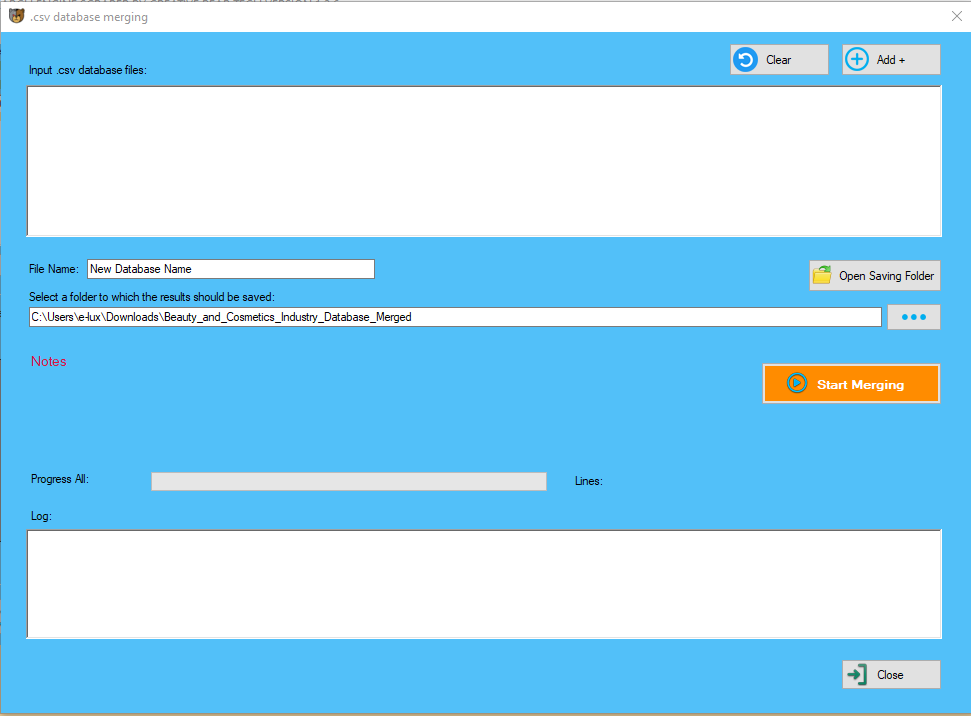 Unearth alpha and radically create value with internet knowledge tailor-made particularly for buyers. The determination-making course of has never been as knowledgeable, nor data as insightful – and the world’s main corporations are more and more consuming net scraped data, given its incredible strategic worth. Revolutionize day-to-day business with web scraped product data and dramatically increase your company’s competitiveness. The final however necessary factor is validation with out it you cannot trust the information. In quick, internet information mining is the process of converting knowledge into genuine data for further use. The content material grabber is a robust big information solution for dependable internet knowledge extraction. It provides easy to use features like visible level and clicks editor. For businesses that want to understand what their clientele – and competition – truly think and really feel, net scraped product data and sentiment analysis are a match made in heaven. Guess no extra and eradicate bias from your interpretations by incorporating and integrating bewildering quantities of relevant, insightful knowledge out of your trade. The digital transformation of real estate prior to now twenty years threatens to disrupt traditional corporations and create powerful new players within the trade. This process is mainly divided into 3 sections; Pre-processing, Extraction, and Validation. The mining department contains information classification, aggregation, error correction, and linking information. Startups, Fortune 500 corporations, and reputed fairness analysts all make choices and derive methods based mostly on knowledge. And in our trendy internet age, one of the simplest ways to get information is through the use of a web scraper. ×Select the specified amount of money you'll be able to spend each month on this knowledge scraping. Tell us about your project or start using our scraping tools today. In this section, we are going to learn the way we can obtain media content material which correctly represents the media type Data Scraping based mostly on the information from web server. We can do it with the help of Python requests module as we did in previous chapter. I love studying new expertise, and I imagine in Always be hungry in the matter of studying and success. It is an interface that makes it much simpler to develop a program by offering the building blocks. In 2000, Salesforce and eBay launched their very own API, with which programmers were enabled to access and obtain a few of the knowledge obtainable to the general public. Since then, many websites supply web APIs for individuals to entry their public database. Data for Machine Learning Projects − Retrieval of information for machine studying initiatives depends upon web scraping. Marketing and Sales Campaigns − Web scrapers can be used to get the info like emails, telephone number etc. for sales and advertising campaigns. In our console, we create a ScrapingBrowser object (our virtual browser) and setup whatever defaults we require. This might embrace permitting (or not) auto re-direct, setting the browser-agent name, allowing cookies etc. Hi, This is Prashant, Experienced Virtual assistant, and Expert In Data Entry, internet research, copy paste and internet scraping. Users could make as many requests as they want, backed by our assure to refund your credits if any scraping request takes longer than 60 seconds. We touched on this industry a bit within the previous section, where we talked about that banking analysts are using social media API scraping to derive helpful funding insights, but that’s only the tip of the iceberg. Through blogs, posts, and comments, clients are creating an absurd quantity of data every day about which companies they like and which of them they'll’t stand. Savvy financiers can use this wealth of buyer data to their advantage – but only if they have an efficient approach to acquire all of it, like a data scraping API. We hope this article has helped you perceive every little thing you should know in regards to the technology of net scraping APIs, which we all know could be pretty intimidating to newcomers. We additionally hope that it has inspired you to make use of Scraping Robot’s new public information scraping API, which we actually consider will present customers with probably the most environment friendly method of focused knowledge assortment.
Unearth alpha and radically create value with internet knowledge tailor-made particularly for buyers. The determination-making course of has never been as knowledgeable, nor data as insightful – and the world’s main corporations are more and more consuming net scraped data, given its incredible strategic worth. Revolutionize day-to-day business with web scraped product data and dramatically increase your company’s competitiveness. The final however necessary factor is validation with out it you cannot trust the information. In quick, internet information mining is the process of converting knowledge into genuine data for further use. The content material grabber is a robust big information solution for dependable internet knowledge extraction. It provides easy to use features like visible level and clicks editor. For businesses that want to understand what their clientele – and competition – truly think and really feel, net scraped product data and sentiment analysis are a match made in heaven. Guess no extra and eradicate bias from your interpretations by incorporating and integrating bewildering quantities of relevant, insightful knowledge out of your trade. The digital transformation of real estate prior to now twenty years threatens to disrupt traditional corporations and create powerful new players within the trade. This process is mainly divided into 3 sections; Pre-processing, Extraction, and Validation. The mining department contains information classification, aggregation, error correction, and linking information. Startups, Fortune 500 corporations, and reputed fairness analysts all make choices and derive methods based mostly on knowledge. And in our trendy internet age, one of the simplest ways to get information is through the use of a web scraper. ×Select the specified amount of money you'll be able to spend each month on this knowledge scraping. Tell us about your project or start using our scraping tools today. In this section, we are going to learn the way we can obtain media content material which correctly represents the media type Data Scraping based mostly on the information from web server. We can do it with the help of Python requests module as we did in previous chapter. I love studying new expertise, and I imagine in Always be hungry in the matter of studying and success. It is an interface that makes it much simpler to develop a program by offering the building blocks. In 2000, Salesforce and eBay launched their very own API, with which programmers were enabled to access and obtain a few of the knowledge obtainable to the general public. Since then, many websites supply web APIs for individuals to entry their public database. Data for Machine Learning Projects − Retrieval of information for machine studying initiatives depends upon web scraping. Marketing and Sales Campaigns − Web scrapers can be used to get the info like emails, telephone number etc. for sales and advertising campaigns. In our console, we create a ScrapingBrowser object (our virtual browser) and setup whatever defaults we require. This might embrace permitting (or not) auto re-direct, setting the browser-agent name, allowing cookies etc. Hi, This is Prashant, Experienced Virtual assistant, and Expert In Data Entry, internet research, copy paste and internet scraping. Users could make as many requests as they want, backed by our assure to refund your credits if any scraping request takes longer than 60 seconds. We touched on this industry a bit within the previous section, where we talked about that banking analysts are using social media API scraping to derive helpful funding insights, but that’s only the tip of the iceberg. Through blogs, posts, and comments, clients are creating an absurd quantity of data every day about which companies they like and which of them they'll’t stand. Savvy financiers can use this wealth of buyer data to their advantage – but only if they have an efficient approach to acquire all of it, like a data scraping API. We hope this article has helped you perceive every little thing you should know in regards to the technology of net scraping APIs, which we all know could be pretty intimidating to newcomers. We additionally hope that it has inspired you to make use of Scraping Robot’s new public information scraping API, which we actually consider will present customers with probably the most environment friendly method of focused knowledge assortment.  Hence we will say that it may be useful to extract the base types of the words while analyzing the textual content. In internet scraping, a very common task is to take screenshot of an internet site. For implementing this, we are going to use selenium and webdriver. The following Python script will take the screenshot from web site and will reserve it to present directory. With the help of following line of code, we are able to save the acquired content as .png file. This is why there is an eternal arms race between scrapers who wish to cross themselves as an actual browser and websites who want to distinguish headless from the rest. The primary downside is that the majority websites don't wish to be scraped. The documentation link above will tell you every little thing you should know to set up an API scraper. Broadly, to use an internet scraping API all you need to do is ship a GET request to the API together with your API key and the URL(s) you would like to scrape. They only wish to serve content to real customers utilizing real web browser (except Google, all of them want to be scraped by Google). Web Scrape is likely one of the leading Web Scraping, Robotic Process Automation service providers throughout the globe at present, which offers a number of benefits to all of the users. Each IP handle must be dealt with like an personal identification and the scraping tool needs to behave like a brand new, believable website consumer. Almost all public websites do use one or a number of layers of scraping protection. Scraping or any type of automated entry to websites is often an unwelcome act.
Hence we will say that it may be useful to extract the base types of the words while analyzing the textual content. In internet scraping, a very common task is to take screenshot of an internet site. For implementing this, we are going to use selenium and webdriver. The following Python script will take the screenshot from web site and will reserve it to present directory. With the help of following line of code, we are able to save the acquired content as .png file. This is why there is an eternal arms race between scrapers who wish to cross themselves as an actual browser and websites who want to distinguish headless from the rest. The primary downside is that the majority websites don't wish to be scraped. The documentation link above will tell you every little thing you should know to set up an API scraper. Broadly, to use an internet scraping API all you need to do is ship a GET request to the API together with your API key and the URL(s) you would like to scrape. They only wish to serve content to real customers utilizing real web browser (except Google, all of them want to be scraped by Google). Web Scrape is likely one of the leading Web Scraping, Robotic Process Automation service providers throughout the globe at present, which offers a number of benefits to all of the users. Each IP handle must be dealt with like an personal identification and the scraping tool needs to behave like a brand new, believable website consumer. Almost all public websites do use one or a number of layers of scraping protection. Scraping or any type of automated entry to websites is often an unwelcome act. 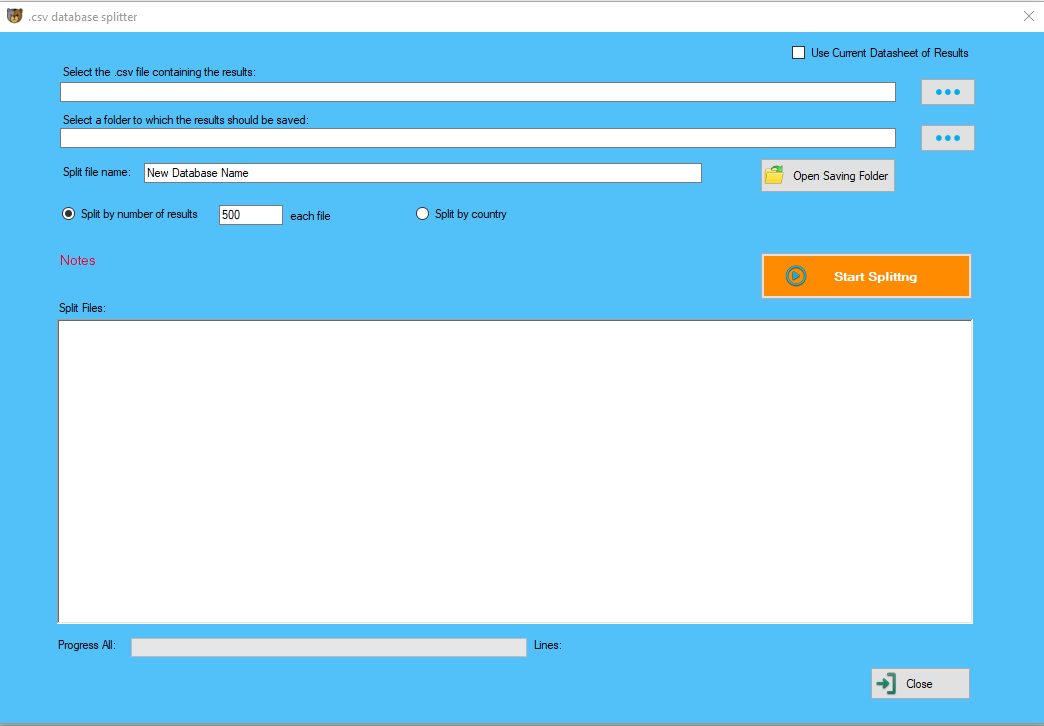
Exercising and Running Outside during Covid-19 (Coronavirus) Lockdown with CBD Oil Tinctures https://t.co/ZcOGpdHQa0 @JustCbd pic.twitter.com/emZMsrbrCk
— Creative Bear Tech (@CreativeBearTec) May 14, 2020